Imagine traverser un tunnel dans un véhicule autonome, sans savoir qu’un accident a bloqué la circulation devant toi. Normalement, tu devrais te fier à la voiture devant toi pour savoir quand commencer à freiner. Mais que se passerait-il si ton véhicule pouvait voir autour de la voiture devant toi et freiner encore plus tôt ?
Des chercheurs du MIT et de Meta ont développé une technique de vision par ordinateur qui pourrait permettre aux véhicules autonomes de faire exactement cela. Ils ont introduit une méthode qui crée des modèles 3D physiquement précis d’une scène entière, y compris les zones masquées, en utilisant des images provenant d’une seule position de caméra. Leur technique utilise les ombres pour déterminer ce qui se trouve dans les parties obstruées de la scène.
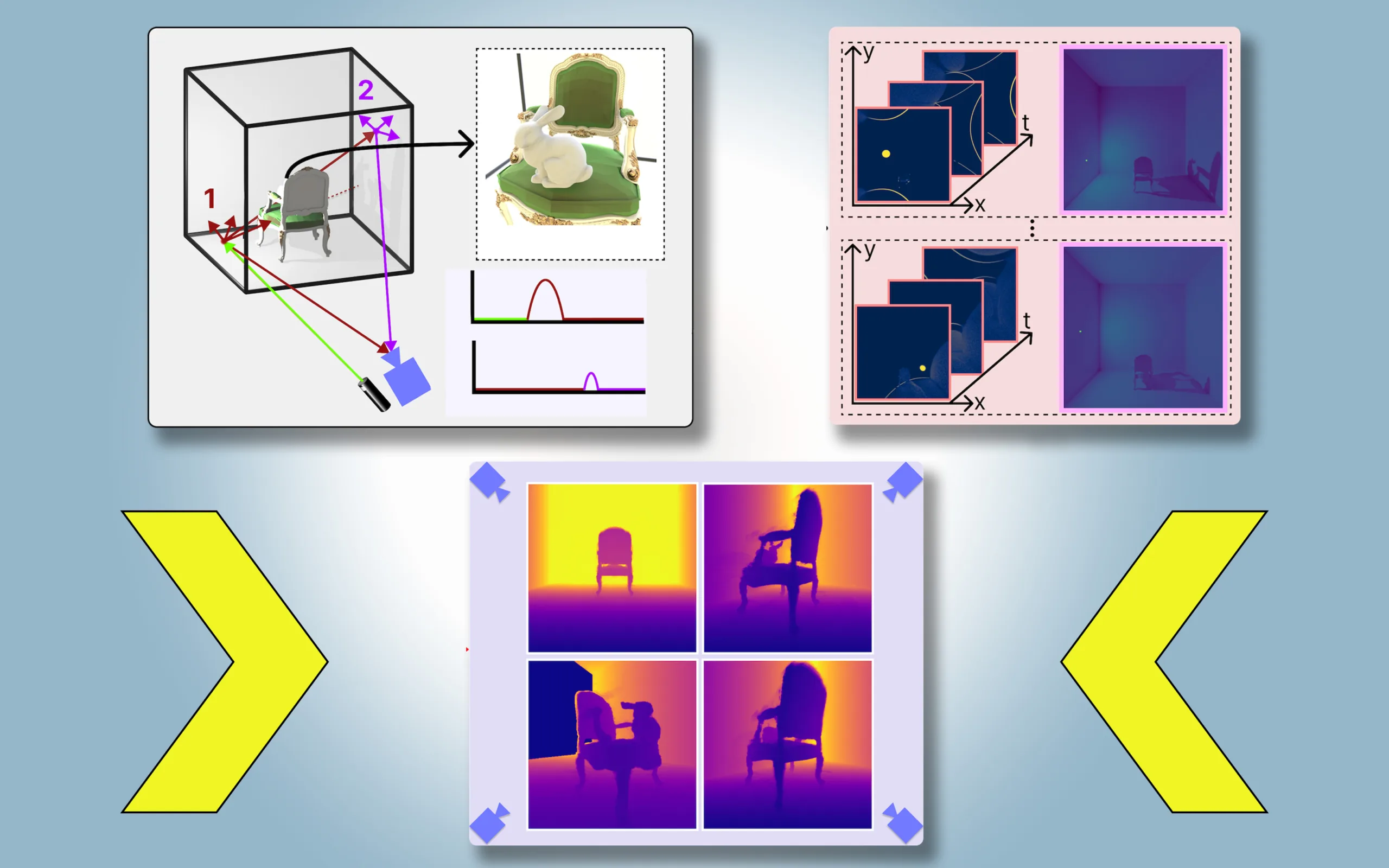
Ils appellent leur approche PlatoNeRF, basée sur l’allégorie de la grotte de Platon, un passage de la « République » du philosophe grec, où des prisonniers enchaînés dans une grotte discernent la réalité du monde extérieur à partir des ombres projetées sur la paroi de la grotte.
En combinant la technologie lidar (détection et télémétrie de la lumière) avec l’apprentissage automatique, PlatoNeRF peut générer des reconstructions plus précises de la géométrie 3D que certaines techniques d’IA existantes. De plus, PlatoNeRF est plus efficace pour reconstruire en douceur les scènes où les ombres sont difficiles à voir, comme celles avec une lumière ambiante élevée ou des arrière-plans sombres.
En plus d’améliorer la sécurité des véhicules autonomes, PlatoNeRF pourrait rendre les casques AR/VR plus efficaces en permettant à un utilisateur de modéliser la géométrie d’une pièce sans avoir besoin de se déplacer pour prendre des mesures. Cela pourrait également aider les robots d’entrepôt à trouver plus rapidement des articles dans des environnements encombrés.
« Notre idée principale était de rassembler ces deux choses qui ont déjà été réalisées dans différentes disciplines : le lidar multi-rebond et l’apprentissage automatique. Il s’avère que lorsque vous réunissez ces deux mondes, vous découvrez de nombreuses nouvelles opportunités d’explorer et de tirer le meilleur parti des deux mondes », explique Tzofi Klinghoffer, étudiant diplômé du MIT en arts et sciences médiatiques, affilié au MIT Media Lab et auteur principal d’un article sur PlatoNeRF.
Klinghoffer a rédigé l’article avec son conseiller, Ramesh Raskar, professeur agrégé d’arts et de sciences médiatiques et chef du Camera Culture Group au MIT; l’auteur principal Rakesh Ranjan, directeur de la recherche sur l’IA chez Meta Reality Labs; ainsi que Siddharth Somasundaram au MIT, et Xiaoyu Xiang, Yuchen Fan et Christian Richardt à Meta. La recherche sera présentée à la conférence sur la vision par ordinateur et la reconnaissance de formes.
### Faire la lumière sur le problème
Reconstruire une scène entièrement 3D à partir d’un seul point de vue de caméra est un problème complexe. Certaines approches d’apprentissage automatique utilisent des modèles d’IA génératifs qui tentent de deviner ce qui se trouve dans les régions obstruées, mais ces modèles peuvent halluciner des objets qui ne sont pas vraiment là. D’autres approches tentent de déduire les formes d’objets cachés à l’aide des ombres dans une image couleur, mais ces méthodes peuvent s’avérer difficiles lorsque les ombres sont difficiles à voir.
Pour PlatoNeRF, les chercheurs du MIT ont développé ces approches en utilisant une nouvelle modalité de détection appelée lidar à photon unique. Les lidars cartographient une scène 3D en émettant des impulsions de lumière et en mesurant le temps nécessaire à cette lumière pour rebondir vers le capteur. Étant donné que les lidars à photon unique peuvent détecter des photons individuels, ils fournissent des données à plus haute résolution.
Les chercheurs utilisent un lidar à photon unique pour éclairer un point cible de la scène. Une partie de la lumière rebondit sur ce point et retourne directement au capteur. Cependant, la majeure partie de la lumière se disperse et rebondit sur d’autres objets avant de revenir au capteur. PlatoNeRF s’appuie sur ces seconds rebonds de lumière.
En calculant le temps nécessaire à la lumière pour rebondir deux fois puis revenir au capteur lidar, PlatoNeRF capture des informations supplémentaires sur la scène, notamment la profondeur. Le deuxième rebond de lumière contient également des informations sur les ombres.
Le système trace les rayons de lumière secondaires – ceux qui rebondissent du point cible vers d’autres points de la scène – pour déterminer quels points se trouvent dans l’ombre (en raison d’une absence de lumière). En fonction de l’emplacement de ces ombres, PlatoNeRF peut déduire la géométrie des objets cachés.
Le lidar éclaire séquentiellement 16 points, capturant plusieurs images utilisées pour reconstruire l’intégralité de la scène 3D.
« Chaque fois que nous éclairons un point de la scène, nous créons de nouvelles ombres. Parce que nous avons toutes ces différentes sources d’éclairage, nous avons beaucoup de rayons lumineux qui se propagent, nous découpons donc la région qui est obstruée et située au-delà de l’œil visible », explique Klinghoffer.
### Une combinaison gagnante
La clé de PlatoNeRF réside dans la combinaison d’un lidar multi-rebond avec un type spécial de modèle d’apprentissage automatique connu sous le nom de champ de radiance neuronale (NeRF). Un NeRF code la géométrie d’une scène dans les poids d’un réseau neuronal, ce qui confère au modèle une forte capacité à interpoler ou à estimer de nouvelles vues d’une scène.
Cette capacité d’interpolation conduit également à des reconstructions de scènes très précises lorsqu’elle est combinée avec un lidar à rebonds multiples, explique Klinghoffer.
« Le plus grand défi a été de trouver comment combiner ces deux choses. Nous avons vraiment dû réfléchir à la physique du transport de la lumière avec le lidar multirebond et à la manière de modéliser cela avec l’apprentissage automatique », dit-il.
Ils ont comparé PlatoNeRF à deux méthodes alternatives courantes, l’une utilisant uniquement le lidar et l’autre utilisant uniquement un NeRF avec une image couleur. Ils ont constaté que leur méthode était capable de surpasser les deux techniques, en particulier lorsque le capteur lidar avait une résolution inférieure. Cela rendrait leur approche plus pratique à déployer dans le monde réel, où les capteurs à faible résolution sont courants dans les appareils commerciaux.
« Il y a environ 15 ans, notre groupe a inventé la première caméra pour « voir » dans les coins, qui fonctionne en exploitant de multiples rebonds de lumière, ou « échos de lumière ». Ces techniques utilisaient des lasers et des capteurs spéciaux et utilisaient trois rebonds de lumière. Depuis lors, la technologie lidar est devenue plus courante, ce qui a conduit à nos recherches sur des caméras capables de voir à travers le brouillard. Cette nouvelle œuvre utilise seulement deux rebonds de lumière, ce qui signifie que le rapport signal/bruit est très élevé et que la qualité de la reconstruction 3D est impressionnante », explique Raskar.
À l’avenir, les chercheurs souhaitent essayer de suivre plus de deux rebonds de lumière pour voir comment cela pourrait améliorer les reconstructions de scènes. En outre, ils souhaitent appliquer des techniques d’apprentissage plus approfondies et combiner PlatoNeRF avec des mesures d’images couleur pour capturer des informations sur la texture.
« Alors que les images d’ombres prises par des caméras ont longtemps été étudiées comme moyen de reconstruction 3D, ce travail revisite le problème dans le contexte du lidar, démontrant des améliorations significatives dans la précision de la géométrie cachée reconstruite. Les travaux montrent comment des algorithmes intelligents peuvent offrir des capacités extraordinaires lorsqu’ils sont combinés avec des capteurs ordinaires, y compris les systèmes lidar que beaucoup d’entre nous transportent désormais dans notre poche », explique David Lindell, professeur adjoint au Département d’informatique de l’Université de Toronto, qui n’a pas participé à ce travail.


