
Image par auteur
Python est un langage de programmation polyvalent et convivial, connu pour sa simplicité et sa lisibilité. Sa syntaxe élégante n’est cependant pas à l’abri de bizarreries qui peuvent surprendre même les développeurs Python expérimentés. Et les comprendre est essentiel pour écrire du code sans bug ou pour un débogage sans problème si vous préférez.
Ce didacticiel explore certains de ces pièges : valeurs par défaut mutables, portée variable dans les boucles et les compréhensions, affectation de tuples, etc. Nous allons coder des exemples simples pour voir pourquoi les choses fonctionnent comme elles le font, et regardez également comment nous pouvons les éviter (si nous le pouvons réellement 🙂).
Alors, commençons!
En Python, les valeurs par défaut mutables sont des angles vifs courants. Vous rencontrerez un comportement inattendu chaque fois que vous définirez une fonction avec des objets mutables, comme des listes ou des dictionnaires, comme arguments par défaut.
La valeur par défaut n’est évaluée qu’une seule fois, lorsque la fonction est définie, et non à chaque fois que la fonction est appelée.. Cela peut entraîner un comportement inattendu si vous modifiez l’argument par défaut dans la fonction.
Prenons un exemple :
def add_to_cart(item, cart=[]):
cart.append(item)
return cartDans cet exemple, add_to_cart est une fonction qui prend un élément et l’ajoute à une liste cart. La valeur par défaut de cart est une liste vide. Cela signifie que l’appel de la fonction sans élément à ajouter renvoie un panier vide.
Et voici quelques appels de fonctions :
# User 1 adds items to their cart
user1_cart = add_to_cart("Apple")
print("User 1 Cart:", user1_cart) Cela fonctionne comme prévu. Mais que se passe-t-il maintenant ?
# User 2 adds items to their cart
user2_cart = add_to_cart("Cookies")
print("User 2 Cart:", user2_cart) Output >>>
['Apple', 'Cookies'] # User 2 never added apples to their cart!Étant donné que l’argument par défaut est une liste (un objet mutable), il conserve son état entre les appels de fonction. Alors chaque fois que tu appelles add_to_cart, il ajoute la valeur au même objet de liste créé lors de la définition de la fonction. Dans cet exemple, c’est comme si tous les utilisateurs partageaient le même panier.
Comment éviter
Pour contourner le problème, vous pouvez définir cart à None et initialisez le panier à l’intérieur de la fonction comme ceci :
def add_to_cart(item, cart=None):
if cart is None:
cart = []
cart.append(item)
return cartAinsi, chaque utilisateur dispose désormais d’un panier distinct. 🙂
Si vous avez besoin d’un rappel sur les fonctions et arguments de fonction Python, lisez Arguments de fonction Python : un guide définitif.
Les bizarreries de Python nécessitent leur propre didacticiel. Mais nous allons examiner ici une de ces bizarreries.
Regardez l’extrait suivant :
x = 10
squares = []
for x in range(5):
squares.append(x ** 2)
print("Squares list:", squares)
# x is accessible here and is the last value of the looping var
print("x after for loop:", x)La variable x est fixé à 10. Mais x est également la variable de boucle. Mais nous supposerions que la portée de la variable de boucle est limitée au bloc de boucle for, n’est-ce pas ?
Regardons le résultat :
Output >>>
Squares list: [0, 1, 4, 9, 16]
x after for loop: 4On voit ça x est maintenant 4, la valeur finale qu’il prend dans la boucle, et non la valeur initiale de 10 à laquelle nous l’avons défini.
Voyons maintenant ce qui se passe si nous remplaçons la boucle for par une expression de compréhension :
x = 10
squares = [x ** 2 for x in range(5)]
print("Squares list:", squares)
# x is 10 here
print("x after list comprehension:", x)Ici, x est 10, la valeur à laquelle nous l’avons défini avant l’expression de compréhension :
Output >>>
Squares list: [0, 1, 4, 9, 16]
x after list comprehension: 10Comment éviter
Pour éviter un comportement inattendu : si vous utilisez des boucles, assurez-vous de ne pas nommer la variable de boucle de la même manière qu’une autre variable à laquelle vous souhaiteriez accéder ultérieurement.
En Python, nous utilisons le is mot-clé pour vérifier l’identité de l’objet. Cela signifie qu’il vérifie si deux variables font référence au même objet en mémoire. Et pour vérifier l’égalité, nous utilisons le == opérateur. Oui?
Maintenant, démarrez un REPL Python et exécutez le code suivant :
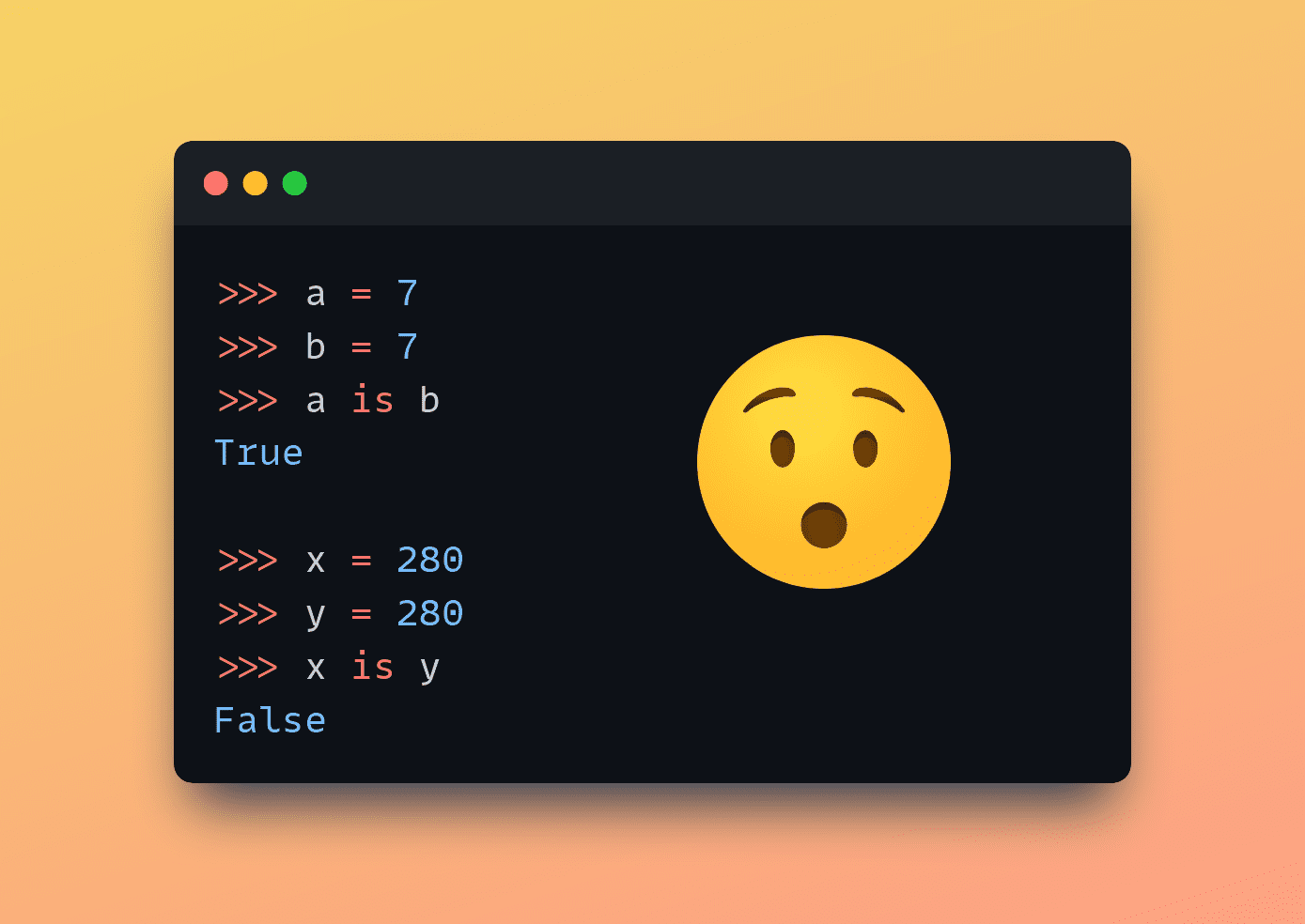
>>> a = 7
>>> b = 7
>>> a == 7
True
>>> a is b
TrueMaintenant, exécutez ceci :
>>> x = 280
>>> y = 280
>>> x == y
True
>>> x is y
FalseAttends, pourquoi est-ce que ça arrive ? Eh bien, cela est dû à la « mise en cache des entiers » ou au « stage » dans CPython, l’implémentation standard de Python.
CPython met en cache les objets entiers dans la plage de -5 à 256. Cela signifie que chaque fois que vous utilisez un entier compris dans cette plage, Python utilisera le même objet en mémoire. Par conséquent, lorsque vous comparez deux entiers dans cette plage à l’aide de la is mot-clé, le résultat est True parce qu’ils faire référence au même objet en mémoire.
C’est pourquoi a is b Retour True. Vous pouvez également le vérifier en imprimant id(a) et id(b).
Toutefois, les entiers situés en dehors de cette plage ne sont pas mis en cache. Et chaque occurrence de tels entiers crée un nouvel objet en mémoire.
Ainsi, lorsque vous comparez deux entiers en dehors de la plage mise en cache à l’aide de l’option is mot-clé (oui, x et y tous deux réglés à 280 dans notre exemple), le résultat est False car ce sont bien deux objets différents en mémoire.
Comment éviter
Ce comportement ne devrait pas poser de problème, sauf si vous essayez d’utiliser le is pour comparer l’égalité de deux objets. Utilisez donc toujours le == opérateur pour vérifier si deux objets Python ont la même valeur.
Si vous êtes familier avec les structures de données intégrées à Python, vous savez que les tuples sont immuable. Alors toi ne peut pas modifiez-les sur place. Les structures de données comme les listes et les dictionnaires, en revanche, sont mutable. C’est à dire toi peut changez-les en place.
Mais qu’en est-il des tuples contenant un ou plusieurs objets mutables ?
Il est utile de démarrer un REPL Python et d’exécuter cet exemple simple :
>>> my_tuple = ([1,2],3,4)
>>> my_tuple[0].append(3)
>>> my_tuple
([1, 2, 3], 3, 4)Ici, le premier élément du tuple est une liste de deux éléments. Nous essayons d’ajouter 3 à la première liste et cela fonctionne bien ! Eh bien, venons-nous de modifier un tuple en place ?
Essayons maintenant d’ajouter deux éléments supplémentaires à la liste, mais cette fois en utilisant l’opérateur += :
>>> my_tuple[0] += [4,5]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'tuple' object does not support item assignment Oui, vous obtenez une TypeError qui indique que l’objet tuple ne prend pas en charge l’affectation d’éléments. Ce qui est attendu. Mais vérifions le tuple :
>>> my_tuple
([1, 2, 3, 4, 5], 3, 4)On voit que les éléments 4 et 5 ont été ajoutés à la liste ! Le programme a-t-il simplement généré une erreur et réussi en même temps ?
Eh bien, l’opérateur += fonctionne en interne en appelant le __iadd__() méthode qui effectue des ajouts sur place et modifie la liste en place. L’affectation déclenche une exception TypeError, mais l’ajout d’éléments à la fin de la liste a déjà réussi. += est peut-être le coin le plus pointu !
Comment éviter
Pour éviter de telles bizarreries dans votre programme, essayez d’utiliser des tuples seulement pour les collections immuables. Et évitez autant que possible d’utiliser des objets mutables comme éléments de tuple.
La mutabilité a été un sujet récurrent dans nos discussions jusqu’à présent. En voici donc un autre pour conclure ce tutoriel.
Parfois, vous devrez peut-être créer des copies indépendantes de listes. Mais que se passe-t-il lorsque vous créez une copie en utilisant une syntaxe similaire à list2 = list1 où list1 est la liste originale ?
C’est une copie superficielle qui est créée. Il copie donc uniquement les références aux éléments originaux de la liste. La modification d’éléments via la copie superficielle affectera les deux la liste originale et la copie superficielle.
Prenons cet exemple :
original_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Shallow copy of the original list
shallow_copy = original_list
# Modify the shallow copy
shallow_copy[0][0] = 100
# Print both the lists
print("Original List:", original_list)
print("Shallow Copy:", shallow_copy)Nous voyons que les modifications apportées à la copie superficielle affectent également la liste originale :
Output >>>
Original List: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]
Shallow Copy: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]Ici, nous modifions le premier élément de la première liste imbriquée dans la copie superficielle : shallow_copy[0][0] = 100. Mais nous voyons que la modification affecte à la fois la liste originale et la copie superficielle.
Comment éviter
Pour éviter cela, vous pouvez créer une copie complète comme ceci :
import copy
original_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Deep copy of the original list
deep_copy = copy.deepcopy(original_list)
# Modify an element of the deep copy
deep_copy[0][0] = 100
# Print both lists
print("Original List:", original_list)
print("Deep Copy:", deep_copy)Désormais, toute modification apportée à la copie complète laisse la liste d’origine inchangée.
Output >>>
Original List: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
Deep Copy: [[100, 2, 3], [4, 5, 6], [7, 8, 9]]Et c’est fini ! Dans ce didacticiel, nous avons exploré plusieurs bizarreries de Python : du comportement surprenant des valeurs par défaut mutables aux subtilités de la copie superficielle de listes. Ceci n’est qu’une introduction aux bizarreries de Python et ne constitue en aucun cas une liste exhaustive. Vous pouvez trouver tous les exemples de code sur GitHub.
Au fur et à mesure que vous continuez à coder en Python et que vous comprenez mieux le langage, vous en rencontrerez peut-être beaucoup plus. Alors continuez à coder, continuez à explorer !
Oh, et faites-nous savoir dans les commentaires si vous souhaitez lire une suite à ce tutoriel.
Bala Priya C est un développeur et rédacteur technique indien. Elle aime travailler à l’intersection des mathématiques, de la programmation, de la science des données et de la création de contenu. Ses domaines d’intérêt et d’expertise incluent le DevOps, la science des données et le traitement du langage naturel. Elle aime lire, écrire, coder et prendre le café ! Actuellement, elle travaille à l’apprentissage et au partage de ses connaissances avec la communauté des développeurs en créant des didacticiels, des guides pratiques, des articles d’opinion, etc. Bala crée également des aperçus de ressources attrayants et des didacticiels de codage.