
Image par auteur
Au cours de la dernière année et demie, le paysage du traitement du langage naturel (NLP) a connu une évolution remarquable, principalement grâce à l’essor des grands modèles de langage (LLM) comme la famille GPT d’OpenAI.
Ces modèles puissants ont révolutionné notre approche de la gestion des tâches en langage naturel, offrant des capacités sans précédent en matière de traduction, d’analyse des sentiments et de génération automatisée de texte. Leur capacité à comprendre et à générer des textes de type humain a ouvert des possibilités autrefois considérées comme inaccessibles.
Cependant, malgré leurs capacités impressionnantes, le parcours de formation de ces modèles est semé d’embûches, tels que le temps et les investissements financiers importants requis.
Cela nous amène au rôle essentiel de la mise au point des LLM.
En affinant ces modèles pré-entraînés pour mieux les adapter à des applications ou à des domaines spécifiques, nous pouvons améliorer considérablement leurs performances sur des tâches particulières. Cette étape améliore non seulement leur qualité, mais étend également leur utilité à un large éventail de secteurs.
Ce guide vise à décomposer ce processus en 7 étapes simples pour affiner tout LLM pour une tâche spécifique.
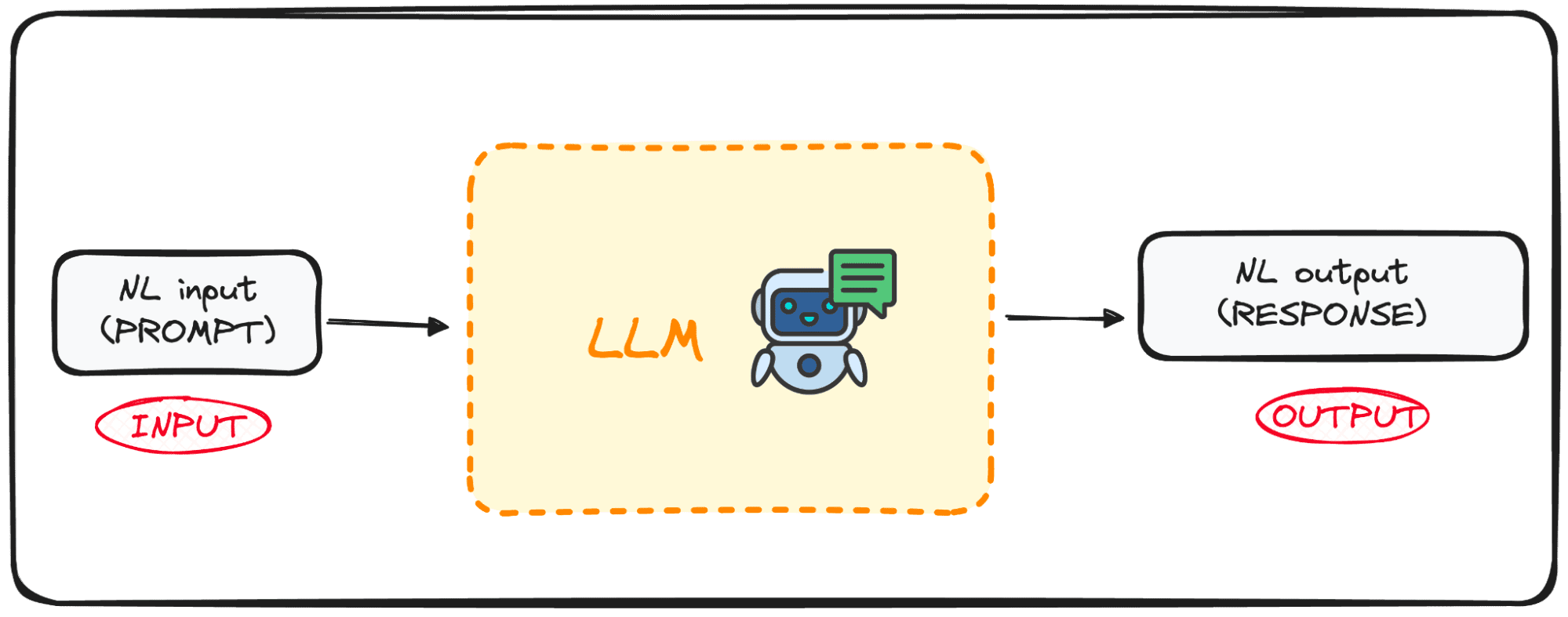
Les LLM sont une catégorie spécialisée d’algorithmes ML conçus pour prédire le mot suivant dans une séquence en fonction du contexte fourni par les mots précédents. Ces modèles reposent sur l’architecture Transformers, une avancée majeure dans les techniques d’apprentissage automatique et expliquée pour la première fois dans le document de Google. Tout ce dont tu as besoin c’est d’attention article.
Des modèles tels que GPT (Generative Pre-trained Transformer) sont des exemples de modèles de langage pré-entraînés qui ont été exposés à de grands volumes de données textuelles. Cette formation approfondie leur permet de saisir les règles sous-jacentes de l’usage du langage, notamment la manière dont les mots sont combinés pour former des phrases cohérentes.

Image par auteur
L’un des principaux atouts de ces modèles réside dans leur capacité non seulement à comprendre le langage naturel, mais également à produire un texte qui imite fidèlement l’écriture humaine en fonction des entrées qui leur sont fournies.
Alors, quel est le meilleur dans tout ça ?
Ces modèles sont déjà ouverts au grand public grâce aux API.
Qu’est-ce que le réglage fin et pourquoi est-ce important ?
Le réglage fin est le processus de sélection d’un modèle pré-entraîné et de son amélioration avec une formation supplémentaire sur un ensemble de données spécifique à un domaine.
La plupart des modèles LLM ont de très bonnes compétences en langage naturel et des connaissances génériques, mais échouent dans des problèmes spécifiques axés sur des tâches. Le processus de réglage fin offre une approche permettant d’améliorer les performances du modèle pour des problèmes spécifiques tout en réduisant les dépenses de calcul sans qu’il soit nécessaire de les construire à partir de zéro.

Image par auteur
Pour faire simple, le réglage fin adapte le modèle pour obtenir de meilleures performances pour des tâches spécifiques, le rendant plus efficace et polyvalent dans les applications du monde réel. Ce processus est essentiel pour améliorer un modèle existant pour une tâche ou un domaine particulier.
Illustrons ce concept en peaufinant un modèle réel en seulement 7 étapes.
Étape 1 : Avoir notre objectif concret clair
Imaginez que nous voulions déduire le sentiment de n’importe quel texte et décidons d’essayer GPT-2 pour une telle tâche.
Je suis presque sûr qu’il n’est pas surprenant que nous détections assez tôt qu’il est assez mauvais dans ce domaine. Ensuite, une question naturelle qui me vient à l’esprit est la suivante :
Pouvons-nous faire quelque chose pour améliorer ses performances ?
Et bien sûr, la réponse est que nous le pouvons !
Profitez du réglage fin en entraînant notre modèle GPT-2 pré-entraîné à partir du Hugging Face Hub avec un ensemble de données contenant des tweets et leurs sentiments correspondants afin que les performances s’améliorent.
Notre objectif ultime est donc avoir un modèle capable de déduire le sentiment à partir du texte.
Étape 2 : Choisissez un modèle pré-entraîné et un ensemble de données
La deuxième étape consiste à choisir le modèle à prendre comme modèle de base. Dans notre cas, nous avons déjà choisi le modèle : GPT-2. Nous allons donc y apporter quelques ajustements simples.

Capture d’écran du hub d’ensembles de données Hugging Face. Sélection du modèle GPT2 d’OpenAI.
Gardez toujours à l’esprit de sélectionner un modèle qui correspond à votre tâche.
Étape 3 : Chargez les données à utiliser
Maintenant que nous avons à la fois notre modèle et notre tâche principale, nous avons besoin de données avec lesquelles travailler.
Mais ne vous inquiétez pas, Hugging Face a tout arrangé !
C’est là qu’intervient leur bibliothèque d’ensembles de données.
Dans cet exemple, nous profiterons de la bibliothèque de jeux de données Hugging Face pour importer un jeu de données avec des tweets étiquetés avec leur sentiment correspondant (positif, neutre ou négatif).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])Les données ressemblent à ceci :

L’ensemble de données à utiliser.
Étape 4 : Tokeniseur
Nous disposons désormais de notre modèle et de l’ensemble de données pour l’affiner. L’étape naturelle suivante consiste donc à charger un tokenizer. Comme les LLM fonctionnent avec des jetons (et non avec des mots !!), nous avons besoin d’un tokeniseur pour envoyer les données à notre modèle.
Nous pouvons facilement réaliser cela en profitant de la méthode map pour tokeniser l’ensemble de données.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)PRIME: Pour améliorer nos performances de traitement, deux sous-ensembles plus petits sont générés :
- L’ensemble de formation : Pour affiner notre modèle.
- L’ensemble de tests : Pour l’évaluer.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))Étape 5 : Initialiser notre modèle de base
Une fois que nous avons l’ensemble de données à utiliser, nous chargeons notre modèle et précisons le nombre d’étiquettes attendues. À partir de l’ensemble de données de sentiments du Tweet, vous pouvez savoir qu’il existe trois étiquettes possibles :
- 0 ou négatif
- 1 ou Neutre
- 2 ou Positif
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)Étape 6 : Évaluer la méthode
La bibliothèque Transformers propose une classe appelée « Trainer » qui optimise à la fois la formation et l’évaluation de notre modèle. Par conséquent, avant de commencer la formation proprement dite, nous devons définir une fonction pour évaluer le modèle affiné.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)Étape 7 : Affiner à l’aide de la méthode du formateur
La dernière étape consiste à affiner le modèle. Pour ce faire, nous mettons en place les arguments de formation avec la stratégie d’évaluation et exécutons l’objet Trainer.
Pour exécuter l’objet Trainer, nous utilisons simplement la commande train().
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()Une fois notre modèle affiné, nous utilisons l’ensemble de test pour évaluer ses performances. L’objet formateur contient déjà une méthode d’évaluation optimisée ().
import evaluate
trainer.evaluate()Il s’agit d’un processus de base pour effectuer un réglage fin de n’importe quel LLM.
N’oubliez pas non plus que le processus de réglage fin d’un LLM est très exigeant en termes de calcul, de sorte que votre ordinateur local n’a peut-être pas assez de puissance pour l’exécuter.
Aujourd’hui, il est crucial d’affiner les grands modèles de langage pré-entraînés comme GPT pour des tâches spécifiques pour améliorer les performances des LLM dans des domaines spécifiques. Cela nous permet de profiter de la puissance de leur langage naturel tout en améliorant leur efficacité et leur potentiel de personnalisation, rendant le processus accessible et rentable.
En suivant ces 7 étapes simples (de la sélection du bon modèle et du bon ensemble de données à la formation et à l’évaluation du modèle affiné), nous pouvons obtenir des performances de modèle supérieures dans des domaines spécifiques.
Pour ceux qui veulent vérifier le code complet, il est disponible dans mon lDe grands modèles de langage dépôt GitHub.
Joseph Ferrer est un ingénieur analytique de Barcelone. Il est diplômé en ingénierie physique et travaille actuellement dans le domaine de la science des données appliquée à la mobilité humaine. Il est créateur de contenu à temps partiel axé sur la science et la technologie des données. Josep écrit sur tout ce qui concerne l’IA, couvrant l’application de l’explosion en cours dans ce domaine.