GCP renforce ses liens avec Nvidia autour des start-ups orientées IA. Outre ce partenariat, Google a dévoilé sa puce personnalisée Axion basée sur Arm pour les centres de données.
Le 9 avril dernier, lors de la conférence Google Cloud Next 2024 (Las Vegas), l’entreprise d’Alphabet a dévoilé une série de produits et services, parmi lesquels un programme destiné à aider les start-ups et les petites entreprises à créer des applications et des services d’IA générative. L’initiative, qui regroupe le programme mondial Nvidia Inception pour les startups et le programme Google for Start-ups Cloud, offre plus d’avantages dont des crédits cloud, un support go-to-market et une expertise technique pour accompagner les jeunes pousses dans leurs projets d’IA. 18 000 start-ups sont déjà soutenues par le programme Inception, et Nvidia cherche à en attirer d’autres en proposant un accès plus rapide à l’infrastructure Google Cloud avec à la clef des crédits GCP et une prime pouvant atteindre jusqu’à 350 000 dollars pour les entreprises axées sur l’IA. En retour, les membres du programme Google for Start-ups Cloud peuvent rejoindre Nvidia Inception et accéder à l’expertise technique, aux crédits de cours du Nvidia Deep Learning Institute, au matériel et aux logiciels Nvidia, etc. Inception propose aussi une plateforme appelée Capital Connect, qui permet aux startups d’entrer en contact avec des sociétés de capital-risque intéressées par le secteur.
Lancement du CPU personnalisé Axion basé sur Arm
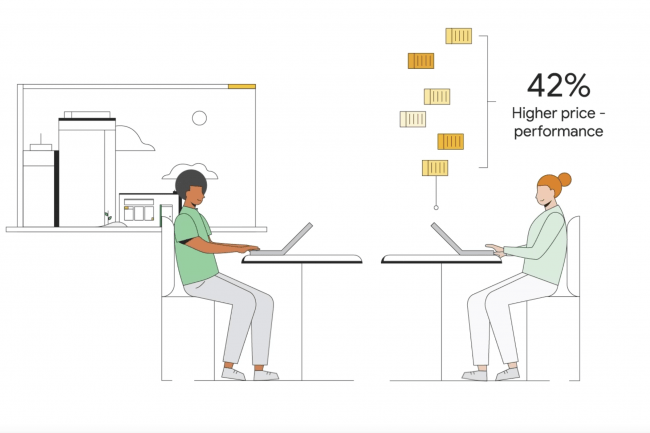
Google a aussi annoncé une gamme de processeurs Arm appelée Axion, pour ses offres de services cloud. Après Amazon Web Services, qui propose des processeurs Graviton (sur base Arm) depuis 2018, et Microsoft, qui a lancé sa propre puce Arm Cobalt 100, à l’automne dernier, Google est ainsi le dernier géant de la technologie à fabriquer ses propres puces personnalisées basées sur Arm. Cependant, ce n’est pas la première incursion de la firme de Mountain View dans le silicium personnalisé. Depuis 2015, l’entreprise a déjà développé des unités de traitement tensoriel (Tensor Processing Unit, TPU) pour l’accélération de ses propres charges de travail, et en 2018, elle a lancé une unité de codage vidéo (Video Coding Unit, VCU) pour le transcodage vidéo. Mais l’Axion sera le premier silicium personnalisé de Google destiné aux clients cloud.
Axion est basé sur l’architecture Neoverse V2 d’Arm, destinée aux charges de travail dans les centres de données. Rappellons qu’Arm ne fabrique pas de puces, mais. des designs qu’elle revend à des détenteurs de licences qui les personnalisent. Certains fabriquent des smartphones (Apple, Qualcomm), d’autres des puces pour serveurs (Ampere). Google s’est refusé à tout commentaire sur les vitesses, les tarifs et les cœurs, mais le fournisseur a affirmé que les processeurs Axion offriraient des instances jusqu’à 30 % plus performantes que les instances polyvalentes Arm les plus rapides disponibles aujourd’hui dans le cloud, jusqu’à 50 % plus performantes et jusqu’à 60 % plus économes en énergie que les instances comparables de la génération actuelle basées sur x86.
La plateforme Axion repose sur Titanium, un système de microcontrôleurs en silicium personnalisés construits par Google et « d’une carte de déchargement dédiée qui permet l’accélération matérielle des services de virtualisation, de façon à décharger le traitement du processeur hôte, et à libérer des ressources pour vos charges de travail », comme l’explique Google. Titanium peut décharger des opérations réseau et de sécurité, de sorte que les processeurs Axion peuvent se concentrer sur le calcul de la charge de travail, de la même manière que le SuperNIC décharge le CPU du traitement du trafic réseau. « Les machines virtuelles basées sur les processeurs Axion seront disponibles en avant-première dans les mois à venir », a précisé Google.
Mise à jour des services logiciels d’IA
En février, Google a présenté Gemma, une suite de modèles ouverts utilisant les mêmes recherches et technologies que celles utilisées pour créer son service d’IA générative Gemini. Aujourd’hui, les équipes de Google et de Nvidia ont travaillé ensemble pour accélérer les performances de Gemma avec TensorRT-LLM de Nvidia, une bibliothèque open-source pour l’optimisation de l’inférence LLM. GCP a également facilité le déploiement du framework NeMo de Nvidia pour la création d’applications d’IA générative personnalisées sur sa plateforme via son moteur GKE Kubernetes et Google Cloud HPC Toolkit. Ce qui permet aux développeurs de démarrer le développement de modèles d’IA générative et de déployer rapidement des produits d’IA clés en main.


