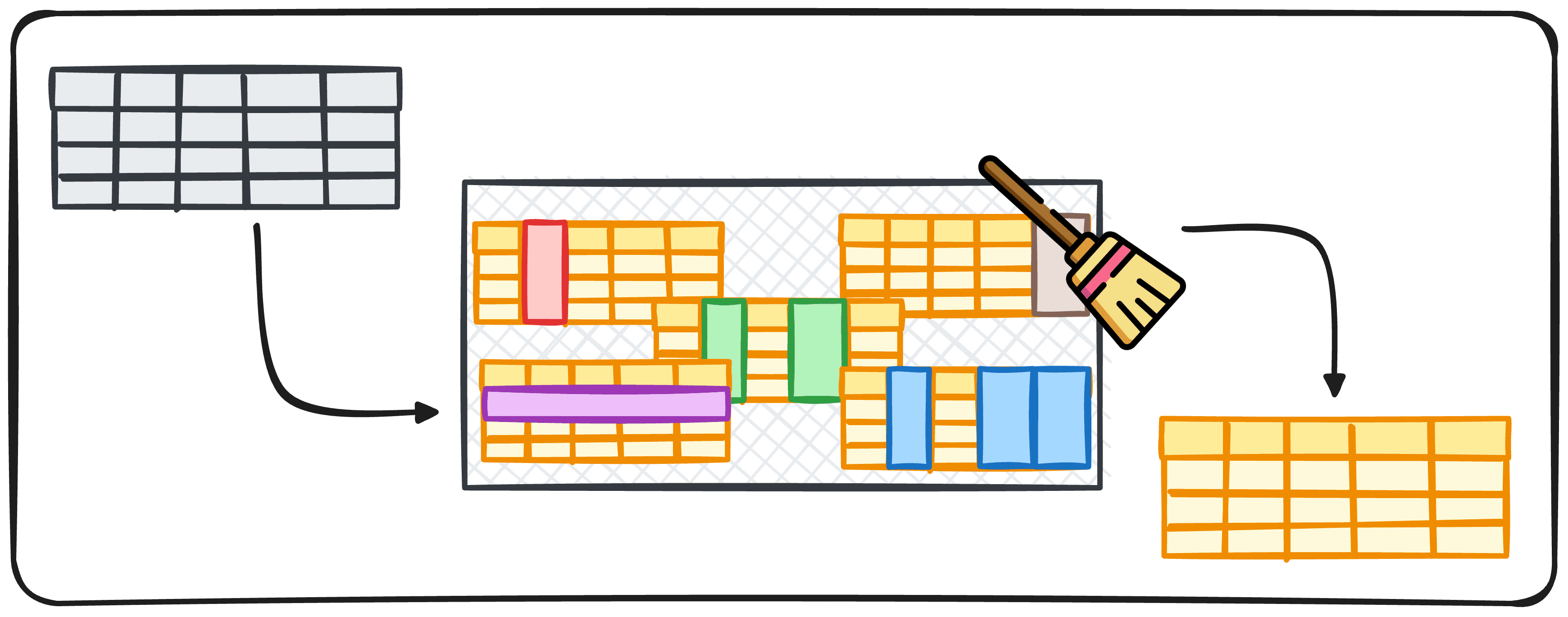

Image par auteur
C’est un fait largement répandu parmi les Data Scientists que le nettoyage des données représente une grande partie de notre temps de travail. Cependant, c’est aussi l’une des parties les moins excitantes. Cela nous amène donc à une question très naturelle :
Existe-t-il un moyen d’automatiser ce processus ?
Automatiser n’importe quel processus est toujours plus facile à dire qu’à faire puisque les étapes à réaliser dépendent principalement du projet et de l’objectif spécifiques. Mais il existe toujours des moyens d’automatiser, au moins certaines parties.
Cet article vise à générer un pipeline avec quelques étapes pour s’assurer que nos données sont propres et prêtes à être utilisées.
Processus de nettoyage des données
Avant de procéder à la génération du pipeline, nous devons comprendre quelles parties des processus peuvent être automatisées.
Puisque nous voulons créer un processus qui peut être utilisé pour presque tous les projets de science des données, nous devons d’abord déterminer quelles étapes sont effectuées encore et encore.
Ainsi, lorsque nous travaillons avec un nouvel ensemble de données, nous posons généralement les questions suivantes :
- Sous quel format arrivent les données ?
- Les données contiennent-elles des doublons ?
- Les données contiennent-elles des valeurs manquantes ?
- Quels types de données les données contiennent-elles ?
- Les données contiennent-elles des valeurs aberrantes ?
Ces 5 questions peuvent facilement être converties en 5 blocs de code pour traiter chacune des questions :
1.Format des données
Les données peuvent se présenter sous différents formats, tels que JSON, CSV ou même XML. Chaque format nécessite son propre analyseur de données. Par exemple, les pandas fournissent read_csv pour les fichiers CSV et read_json pour les fichiers JSON.
En identifiant le format, vous pouvez choisir le bon outil pour commencer le processus de nettoyage.
Nous pouvons facilement identifier le format du fichier que nous traitons en utilisant la fonction path.plaintext de la bibliothèque os. Par conséquent, nous pouvons créer une fonction qui détermine d’abord quelle extension nous avons, puis s’applique directement à l’analyseur correspondant.
2. Doublons
Il arrive assez souvent que certaines lignes de données contiennent exactement les mêmes valeurs que d’autres lignes, ce que nous appelons des doublons. Les données dupliquées peuvent fausser les résultats et conduire à des analyses inexactes, ce qui n’est pas bon du tout.
C’est pourquoi nous devons toujours nous assurer qu’il n’y a pas de doublons.
Pandas nous a couvert avec la méthode drop_duplicate(), qui efface toutes les lignes dupliquées d’une trame de données.
Nous pouvons créer une fonction simple qui utilise cette méthode pour supprimer tous les doublons. Si nécessaire, nous ajoutons une variable d’entrée de colonnes qui adapte la fonction pour éliminer les doublons en fonction d’une liste spécifique de noms de colonnes.
3. Valeurs manquantes
Les données manquantes sont également un problème courant lorsque l’on travaille avec des données. Selon la nature de vos données, nous pouvons simplement supprimer les observations contenant des valeurs manquantes, ou nous pouvons combler ces lacunes en utilisant des méthodes telles que le remplissage avant, le remplissage en arrière ou la substitution par la moyenne ou la médiane de la colonne.
Pandas nous propose les méthodes .fillna() et .dropna() pour gérer efficacement ces valeurs manquantes.
Le choix de la manière dont nous traitons les valeurs manquantes dépend :
- Le type de valeurs manquantes
- La proportion de valeurs manquantes par rapport au nombre total d’enregistrements dont nous disposons.
Gérer les valeurs manquantes est une tâche assez complexe à réaliser – et généralement l’une des plus importantes ! – vous pouvez en apprendre davantage dans l’article suivant.
Pour notre pipeline, nous vérifierons d’abord le nombre total de lignes présentant des valeurs nulles. Si seulement 5 % d’entre eux ou moins sont concernés, nous effacerons ces enregistrements. Dans le cas où plusieurs lignes présentent des valeurs manquantes, nous vérifierons colonne par colonne et procéderons soit :
- Imputation de la médiane de la valeur.
- Générez un avertissement pour approfondir vos recherches.
Dans ce cas, nous évaluons les valeurs manquantes avec un processus de validation humaine hybride. Comme vous le savez déjà, l’évaluation des valeurs manquantes est une tâche cruciale qui ne peut être négligée.
Lorsque vous travaillez avec des types de données normaux, nous pouvons procéder à la transformation des colonnes directement avec la fonction pandas .astype(), afin que vous puissiez réellement modifier le code pour générer des conversations régulières.
Sinon, il est généralement trop risqué de supposer qu’une transformation s’effectuera sans problème lorsque l’on travaille avec de nouvelles données.
5. Gérer les valeurs aberrantes
Les valeurs aberrantes peuvent affecter considérablement les résultats de votre analyse de données. Les techniques permettant de gérer les valeurs aberrantes incluent la définition de seuils, le plafonnement des valeurs ou l’utilisation de méthodes statistiques telles que le score Z.
Afin de déterminer si nous avons des valeurs aberrantes dans notre ensemble de données, nous utilisons une règle commune et considérons tout enregistrement en dehors de la plage suivante comme une valeur aberrante. [Q1 — 1.5 * IQR , Q3 + 1.5 * IQR]
Où IQR représente l’intervalle interquartile et Q1 et Q3 sont les 1er et 3ème quartiles. Ci-dessous, vous pouvez observer tous les concepts précédents affichés dans une boîte à moustaches.

Image par auteur
Pour détecter la présence de valeurs aberrantes, nous pouvons facilement définir une fonction qui vérifie quelles colonnes présentent des valeurs hors de la plage précédente et génère un avertissement.
Dernières pensées
Le nettoyage des données est une partie cruciale de tout projet de données, mais c’est également généralement la phase la plus ennuyeuse et la plus longue. C’est pourquoi cet article distille efficacement une approche globale dans un pipeline pratique en 5 étapes pour automatiser le nettoyage des données à l’aide de Python et.
Le pipeline ne consiste pas seulement à implémenter du code. Il intègre des critères de prise de décision réfléchis qui guident l’utilisateur dans la gestion de différents scénarios de données.
Ce mélange d’automatisation et de surveillance humaine garantit à la fois efficacité et précision, ce qui en fait une solution robuste pour les data scientists souhaitant optimiser leur flux de travail.
Vous pouvez aller vérifier tout mon code ci-dessous Dépôt GitHub.
Joseph Ferrer est un ingénieur analytique de Barcelone. Il est diplômé en ingénierie physique et travaille actuellement dans le domaine de la science des données appliquée à la mobilité humaine. Il est créateur de contenu à temps partiel axé sur la science et la technologie des données. Josep écrit sur tout ce qui concerne l’IA, couvrant l’application de l’explosion en cours dans ce domaine.


