Les modèles de base sont des modèles d’apprentissage profond massifs pré-entraînés sur une vaste quantité de données non étiquetées à usage général. Ils peuvent être utilisés pour diverses tâches, telles que la génération d’images ou la réponse aux questions des clients.
Cependant, ces modèles, qui alimentent des outils d’intelligence artificielle puissants comme ChatGPT et DALL-E, peuvent parfois fournir des informations incorrectes ou trompeuses. Dans des situations critiques pour la sécurité, comme lorsqu’un piéton s’approche d’une voiture autonome, ces erreurs pourraient avoir des conséquences graves.
Pour éviter de telles erreurs, des chercheurs du MIT et du MIT-IBM Watson AI Lab ont développé une technique pour estimer la fiabilité des modèles de base avant leur déploiement pour des tâches spécifiques.
Ils considèrent un ensemble de modèles de base légèrement différents et utilisent un algorithme pour évaluer la cohérence des représentations que chaque modèle apprend sur le même point de données de test. Si les représentations sont cohérentes, le modèle est jugé fiable.
Comparée aux méthodes de pointe actuelles, leur technique s’est révélée plus efficace pour évaluer la fiabilité des modèles de base sur diverses tâches de classification en aval.
Cette technique pourrait être utilisée pour décider si un modèle doit être appliqué dans un certain contexte sans nécessiter de tests sur un ensemble de données réel. Cela est particulièrement utile lorsque les ensembles de données ne sont pas accessibles en raison de problèmes de confidentialité, comme dans les établissements de soins de santé. De plus, la technique pourrait classer les modèles en fonction de scores de fiabilité, permettant ainsi aux utilisateurs de sélectionner le meilleur modèle pour leur tâche.
« Tous les modèles peuvent se tromper, mais les modèles qui savent quand ils se trompent sont plus utiles. Quantifier l’incertitude ou la fiabilité est plus difficile pour ces modèles de base car leurs représentations abstraites sont difficiles à comparer. Notre méthode permet de quantifier la fiabilité d’un modèle de représentation pour des données d’entrée données », explique Navid Azizan, professeur adjoint au département de génie mécanique du MIT et à l’Institut des données, des systèmes et de la société (IDSS), et membre du Laboratoire des systèmes d’information et de décision (LIDS).
Il est rejoint sur un article sur le sujet par Young-Jin Park, étudiant diplômé du LIDS ; Hao Wang, chercheur scientifique au MIT-IBM Watson AI Lab ; et Shervin Ardeshir, chercheur scientifique principal chez Netflix. Le document sera présenté à la Conférence sur l’incertitude dans l’intelligence artificielle.
Mesurer le consensus
Les modèles d’apprentissage automatique traditionnels sont formés pour effectuer une tâche spécifique et font généralement une prédiction concrète basée sur une entrée. Par exemple, un modèle peut indiquer si une image contient un chat ou un chien. Dans ce cas, évaluer la fiabilité consiste à examiner la prédiction finale pour voir si le modèle est correct.
Les modèles de base sont différents. Ils sont pré-entraînés avec des données générales sans connaître toutes les tâches en aval auxquelles ils seront appliqués. Les utilisateurs les adaptent ensuite à leurs tâches spécifiques.
Contrairement aux modèles d’apprentissage automatique traditionnels, les modèles de base ne fournissent pas de résultats concrets comme des étiquettes « chat » ou « chien ». Ils génèrent plutôt une représentation abstraite basée sur un point de données d’entrée.
Pour évaluer la fiabilité d’un modèle de base, les chercheurs ont utilisé une approche d’ensemble en entraînant plusieurs modèles partageant de nombreuses propriétés mais légèrement différents.
« Notre idée est de mesurer le consensus. Si tous ces modèles de base donnent des représentations cohérentes pour toutes les données de notre ensemble de données, alors nous pouvons dire que ce modèle est fiable », explique Park.
Ils ont cependant rencontré un problème : comment comparer des représentations abstraites ?
« Ces modèles génèrent simplement un vecteur composé de quelques nombres, nous ne pouvons donc pas les comparer facilement », ajoute-t-il.
Ils ont résolu ce problème en utilisant une idée appelée cohérence de quartier.
Pour leur approche, les chercheurs préparent un ensemble de points de référence fiables à tester sur l’ensemble des modèles. Ensuite, pour chaque modèle, ils étudient les points de référence situés à proximité de la représentation du point de test par ce modèle.
En regardant la cohérence des points voisins, ils peuvent estimer la fiabilité des modèles.
Aligner les représentations
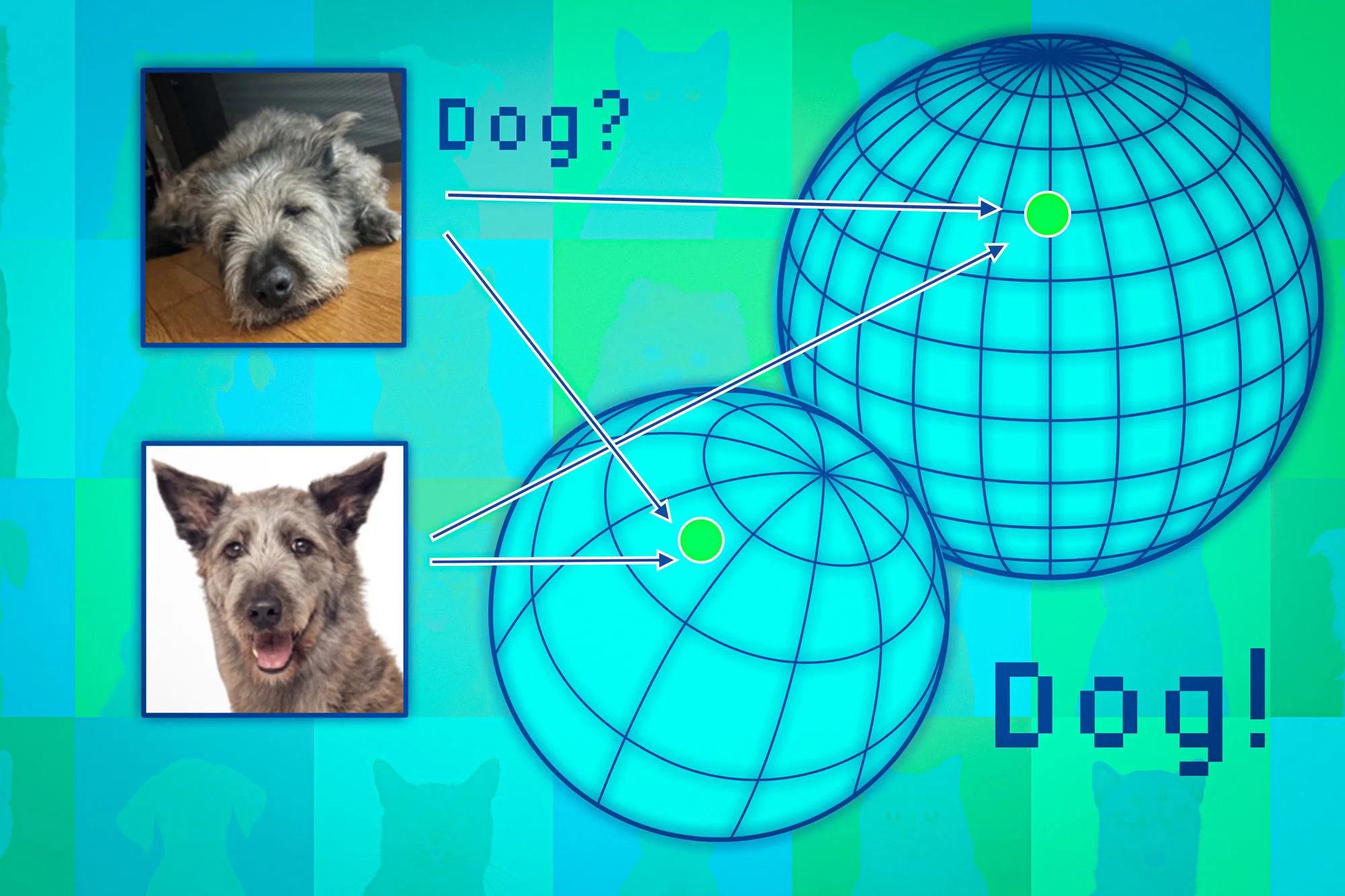
Les modèles de base mappent les points de données vers ce que l’on appelle un espace de représentation. Une façon de penser cet espace est de le considérer comme une sphère. Chaque modèle mappe des points de données similaires sur la même partie de sa sphère, de sorte que les images de chats vont à un endroit et les images de chiens à un autre.
Mais chaque modèle cartographierait les animaux différemment dans sa propre sphère. Ainsi, même si les chats peuvent être regroupés près du pôle Sud d’une sphère, un autre modèle pourrait cartographier les chats quelque part dans l’hémisphère Nord.
Les chercheurs utilisent les points voisins comme des ancres pour aligner ces sphères afin de rendre les représentations comparables. Si les voisins d’un point de données sont cohérents dans plusieurs représentations, alors il faut être sûr de la fiabilité de la sortie du modèle pour ce point.
Lorsqu’ils ont testé cette approche sur un large éventail de tâches de classification, ils ont constaté qu’elle était beaucoup plus cohérente que les lignes de base. De plus, elle n’a pas été déclenchée par des points de test difficiles qui ont provoqué l’échec d’autres méthodes.
De plus, leur approche peut être utilisée pour évaluer la fiabilité de n’importe quelle donnée d’entrée, de sorte que l’on puisse évaluer dans quelle mesure un modèle fonctionne pour un type particulier d’individu, tel qu’un patient présentant certaines caractéristiques.
« Même si les modèles ont tous des performances globales moyennes, d’un point de vue individuel, vous préférerez celui qui fonctionne le mieux pour cet individu », explique Wang.
Cependant, une limitation vient du fait qu’ils doivent former un ensemble de modèles de base, ce qui est coûteux en termes de calcul. À l’avenir, ils envisagent de trouver des moyens plus efficaces de construire plusieurs modèles, peut-être en utilisant de petites perturbations d’un seul modèle.
« Avec la tendance actuelle à utiliser des modèles fondamentaux pour leurs intégrations afin de prendre en charge diverses tâches en aval – du réglage fin à la génération augmentée de récupération – le sujet de la quantification de l’incertitude au niveau de la représentation est de plus en plus important, mais difficile, car les intégrations en elles-mêmes n’ont pas de mise à la terre. Ce qui compte plutôt, c’est la manière dont les intégrations de différentes entrées sont liées les unes aux autres, une idée que ce travail reflète parfaitement grâce au score de cohérence de voisinage proposé », explique Marco Pavone, professeur agrégé au Département d’aéronautique et d’astronautique de l’Université de Stanford, qui n’a pas été impliqué dans ce travail. « Il s’agit d’une étape prometteuse vers des quantifications d’incertitude de haute qualité pour l’intégration de modèles, et je suis ravi de voir de futures extensions qui peuvent fonctionner sans nécessiter d’assemblage de modèles pour vraiment permettre à cette approche d’évoluer vers des modèles de taille fondamentale. »
Ce travail est financé en partie par le MIT-IBM Watson AI Lab, MathWorks et Amazon.