Dernièrement, je me suis concentré sur la narration des données et sur son importance pour communiquer efficacement les résultats de l’analyse des données afin de générer de la valeur. Cependant, mon parcours technique, très proche du monde de la gestion des données et de ses problématiques, m’a poussé à réfléchir sur ce dont la gestion des données a besoin pour pouvoir construire rapidement des histoires basées sur les données. Je suis arrivé à une conclusion qui est souvent tenue pour acquise mais qu’il est toujours bon de garder à l’esprit. Vous ne pouvez pas vous fier uniquement aux données pour créer des histoires basées sur les données. Il est également nécessaire qu’un système de gestion de données prenne en compte au moins deux aspects. Voulez-vous savoir lesquels ? Essayons de le découvrir dans cet article.
Ce que nous allons aborder dans cet article :
- Présentation des données
- Systèmes de gestion de données
- Narration de données
- Gestion des données et narration des données
1. Présentation des données
Nous parlons, utilisons et générons continuellement des données. Mais vous êtes-vous demandé ce que sont les données et quels types de données existent ? Essayons de le définir.
Les données sont des faits bruts, des chiffres ou des symboles qui peuvent être traités pour générer des informations significatives. Il existe différents types de données :
- Données structurées Ce sont des données organisées dans un schéma fixe, tel que SQL ou CSV. Les principaux avantages de ce type de données sont qu’il est facile d’en tirer des informations. Le principal inconvénient est que la dépendance au schéma limite l’évolutivité. Une base de données est un exemple de ce type de données.
- Données semi-structurées est partiellement organisé sans schéma fixe, tel que JSON XML. L’avantage est qu’elles sont plus flexibles que les données structurées. Le principal inconvénient est que la structure au niveau méta peut contenir des données non structurées. Les exemples sont des textes annotés, tels que des tweets avec des hashtags.
- Données non structurées, tels que l’audio, la vidéo et le texte, ne sont pas annotés. Les principaux avantages sont qu’ils ne sont pas structurés, il est donc facile de les stocker. Ils sont également très évolutifs. Cependant, ils sont difficiles à gérer. Par exemple, il est difficile d’en extraire du sens. Le texte brut et les photos numériques sont des exemples de données non structurées.
Pour organiser des données dont le volume augmente avec le temps, il est essentiel de bien les gérer.
2. Gestion des données
La gestion des données est la pratique consistant à ingérer, traiter, sécuriser et stocker les données d’une organisation, qui sont ensuite utilisées pour la prise de décision stratégique afin d’améliorer les résultats commerciaux. [1]. Il existe trois systèmes centraux de gestion des données :
- Entrepôt de données
- Lac de données
- Données Lakehouse
2.1 Entrepôt de données
Un entrepôt de données ne peut gérer que les processus structurés de post-extraction, de transformation et de chargement (ETL). Une fois élaborées, les données peuvent être utilisées à des fins de reporting, de création de tableaux de bord ou d’exploration. La figure suivante résume la structure d’un entrepôt de données.

Fig. 1 : L’architecture d’un entrepôt de données
Les principaux problèmes des entrepôts de données sont :
- Évolutivité – ils ne sont pas évolutifs
- Données non structurées – ils ne gèrent pas les données non structurées
- Données en temps réel – ils ne gèrent pas les données en temps réel.
2.2 Lac de données
Un Data Lake peut ingérer des données brutes telles quelles. Contrairement à un entrepôt de données, un lac de données gère et fournit des moyens de consommer ou de traiter des données structurées, semi-structurées et non structurées. L’ingestion de données brutes permet à un lac de données d’ingérer des données historiques et en temps réel dans un système de stockage brut.
Le lac de données ajoute une couche de métadonnées et de gouvernance, comme le montre la figure suivante, pour rendre les données consommables par les couches supérieures (rapports, tableaux de bord et exploration de données). La figure suivante montre l’architecture d’un lac de données.

Fig. 2 : L’architecture d’un lac de données
Le principal avantage d’un data lake est qu’il peut ingérer rapidement tout type de données puisqu’il ne nécessite aucun traitement préalable. Le principal inconvénient d’un lac de données est que puisqu’il ingère des données brutes, il ne prend pas en charge le système sémantique et transactionnel de l’entrepôt de données.
2.3 Lac de données
Au fil du temps, le concept de lac de données a évolué pour devenir le lac de données, un lac de données augmenté qui inclut la prise en charge des transactions à son sommet. En pratique, un Data Lakehouse modifie les données existantes dans le Data Lake, en suivant la sémantique de l’entrepôt de données, comme le montre la figure suivante.

Fig. 3 : L’architecture d’un data lakehouse
Le data Lakehouse ingère les données extraites de sources opérationnelles, telles que des données structurées, semi-structurées et non structurées. Il le fournit aux applications d’analyse, telles que les rapports, les tableaux de bord, les espaces de travail et les applications. Un data lakehouse comprend les principaux composants suivants :
- Lac de données, qui inclut le format de table, le format de fichier et le magasin de fichiers
- Couche de science des données et d’apprentissage automatique
- Moteur de requête
- Couche de gestion des métadonnées
- Couche de gouvernance des données.
2.4 Généralisation de l’architecture du système de gestion des données
La figure suivante généralise l’architecture du système de gestion de données.

Fig. 4. L’architecture générale d’un système de gestion de données
Un système de gestion de données (entrepôt de données, lac de données, lac de données ou autre) reçoit des données en entrée et génère une sortie (rapports, tableaux de bord, espaces de travail, applications,…). Les intrants sont générés par des personnes et les résultats sont à nouveau exploités par des personnes. Ainsi, nous pouvons dire que nous avons des personnes en entrée et des personnes en sortie. Un système de gestion de données va de personne à personne.
Les personnes participantes incluent les personnes qui génèrent les données, telles que les personnes portant des capteurs, les personnes répondant à des enquêtes, les personnes rédigeant un avis sur quelque chose, les statistiques sur les personnes, etc. Les personnes en sortie peuvent appartenir à l’une des trois catégories suivantes :
- Grand publicdont l’objectif est d’apprendre quelque chose ou de se divertir
- Professionnelsqui sont des techniciens souhaitant comprendre les données
- Cadres qui prennent les décisions.
Dans cet article, nous nous concentrerons sur les dirigeants car ils génèrent de la valeur.
Mais comment ça valeur? Le dictionnaire Cambridge donne différentes définitions de la valeur [2].
- Le somme d’argent qui peut être reçu pour quelque chose
- Le importance ou valeur de quelque chose pour quelqu’un
- Valeurs : les croyances que les gens ont, en particulier sur ce qui est bien et mal et sur ce qui est le plus important dans la vie, qui contrôlent leur comportement.
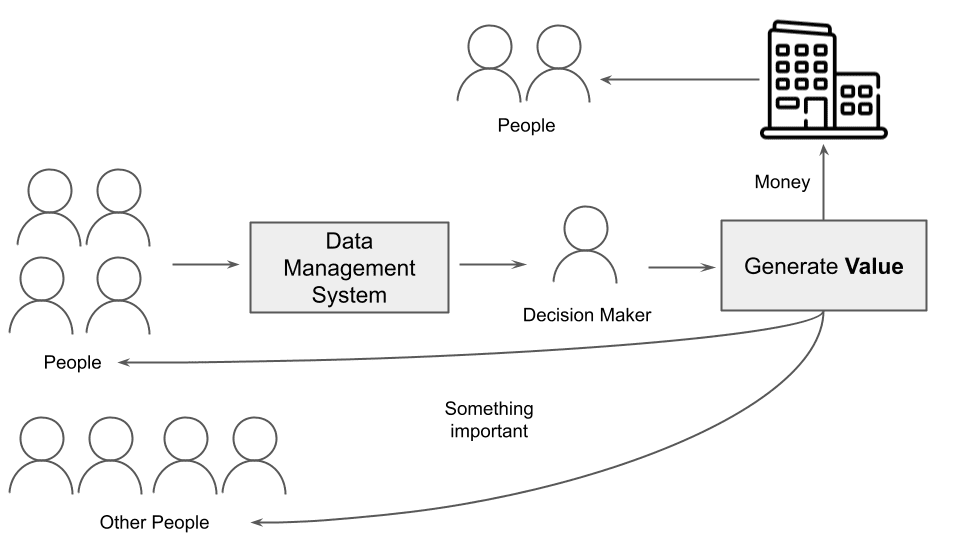
Si nous acceptons la définition de la valeur comme montant d’argent, un décideur pourrait générer de la valeur pour l’entreprise pour laquelle il travaille et indirectement pour les personnes dans l’entreprise et les personnes utilisant les services ou produits proposés par l’entreprise. Si nous acceptons la définition de la valeur comme l’importance de quelque chose, la valeur est essentielle pour les personnes qui génèrent des données et pour d’autres personnes externes, comme le montre la figure suivante.

Fig. 5 : Le processus de génération de valeur
Dans ce scénario, communiquer correctement et efficacement les données aux décideurs devient crucial pour générer de la valeur. Pour cette raison, l’ensemble du pipeline de données doit être conçu pour communiquer les données au public final (les décideurs) afin de générer de la valeur.
3. Narration des données
Il existe trois manières de communiquer des données :
- Rapport de données comprend la description des données, avec tous les détails des phases d’exploration et d’analyse des données.
- Présentation des données sélectionne uniquement les données pertinentes et les montre au public final de manière organisée et structurée.
- Narration de données construit une histoire sur les données.
Concentrons-nous sur la narration des données. Le Data Storytelling consiste à communiquer les résultats d’un processus d’analyse de données à un public à travers une histoire. En fonction de votre audience, vous choisirez une
- Langue et ton: L’ensemble des mots (langage) et l’expression émotionnelle véhiculée à travers eux (ton)
- Contexte: Le niveau de détails à ajouter à votre histoire, en fonction de la sensibilité culturelle du public
Le Data Storytelling doit prendre en compte les données et toutes les informations pertinentes associées aux données (contexte). Le contexte des données fait référence aux informations de base et aux détails pertinents entourant et décrivant un ensemble de données. Dans les pipelines de données, ce contexte de données est stocké sous forme de métadonnées [3]. Métadonnées devrait apporter des réponses aux questions suivantes :
- Qui a collecté les données
- De quoi parlent les données
- Quand les données ont été collectées
- Où les données ont été collectées
- Pourquoi les données ont été collectées
- Comment les données ont été collectées
3.1 L’importance des métadonnées
Revoyons le pipeline de gestion des données du point de vue de la narration des données, qui inclut les données et les métadonnées (contexte)

Fig. 6 : Le pipeline de gestion des données du point de vue de la narration des données
Le système de gestion des données comprend deux éléments : la gestion des données, où l’acteur principal est l’ingénieur de données et l’analyse des données, où l’acteur principal est le data scientist.
L’ingénieur de données doit se concentrer non seulement sur les données mais également sur les métadonnées, ce qui aide le data scientist à construire le contexte autour des données. Il existe deux types de systèmes de gestion de métadonnées :
- Gestion passive des métadonnées, qui regroupe et stocke les métadonnées dans un catalogue de données statique (par exemple, Apache Hive)
- Gestion active des métadonnées, qui fournit des métadonnées dynamiques et en temps réel (par exemple, Apache Atlas)
Le data scientist doit construire une histoire basée sur les données.
4. Gestion des données et narration des données
Combiner Data Management et Data Storytelling signifie :
- Considérant les personnes finales qui bénéficieront des données. Un système de gestion de données va de personne à personne.
- Pensez aux métadonnées, qui aident à créer les histoires les plus puissantes.
Si nous examinons l’ensemble du pipeline de données du point de vue des résultats souhaités, nous découvrons l’importance des personnes derrière chaque étape. Nous ne pouvons générer de la valeur à partir des données que si nous examinons les personnes qui se cachent derrière ces données.
Résumé
Toutes nos félicitations! Vous venez d’apprendre à aborder la gestion des données du point de vue du Data Storytelling. Vous devez considérer deux aspects, en plus des données :
- Les gens derrière les données
- Métadonnées, qui donnent du contexte à vos données.
Et surtout, n’oubliez jamais les gens ! La narration de données vous aide à examiner les histoires qui se cachent derrière les données !
Les références
[1] IBM. Qu’est-ce que la gestion des données ?
[2] Le dictionnaire Cambridge. Valeur.
[3] Pierre Crocker. Guide pour améliorer le contexte des données : qui, quoi, quand, où, pourquoi et comment
Ressources externes
Utiliser le Data Storytelling pour transformer les données en valeur [talk]
Angélique Lo Duca (Moyen) (@alod83) est chercheur à l’Institut d’informatique et de télématique du Conseil national de la recherche (IIT-CNR) à Pise, en Italie. Elle est professeur de « Data Journalism » pour le Master en Humanités Numériques de l’Université de Pise. Ses intérêts de recherche incluent la science des données, l’analyse des données, l’analyse de texte, les données ouvertes, les applications Web, l’ingénierie des données et le journalisme de données, appliqués à la société, au tourisme et au patrimoine culturel. Elle est l’auteur du livre Comet for Data Science, publié par Packt Ltd., du prochain livre Data Storytelling in Python Altair and Generative AI, publié par Manning, et co-auteur du prochain livre Learning and Operating Presto, de O ‘Reilly Médias. Angelica est également une rédactrice technique enthousiaste.