Les modèles climatiques constituent une technologie clé pour prédire les impacts du changement climatique. En exécutant des simulations du climat terrestre, les scientifiques et les décideurs politiques peuvent estimer des conditions telles que l’élévation du niveau de la mer, les inondations et la hausse des températures, et prendre des décisions sur la manière d’y réagir de manière appropriée. Mais les modèles climatiques actuels ont du mal à fournir ces informations suffisamment rapidement ou à un coût abordable pour être utiles à des échelles plus petites, comme la taille d’une ville.
Or, les auteurs d’un nouveau document en libre accès publié dans le Journal des avancées dans la modélisation des systèmes terrestres ont trouvé une méthode pour tirer parti de l’apprentissage automatique afin d’exploiter les avantages des modèles climatiques actuels, tout en réduisant les coûts de calcul nécessaires à leur exécution.
«Cela renverse la sagesse traditionnelle», déclare Sai Ravela, chercheur principal au Département des sciences de la Terre, de l’atmosphère et des planètes (EAPS) du MIT, qui a rédigé l’article avec Anamitra Saha, postdoctorante à l’EAPS.
Sagesse traditionnelle
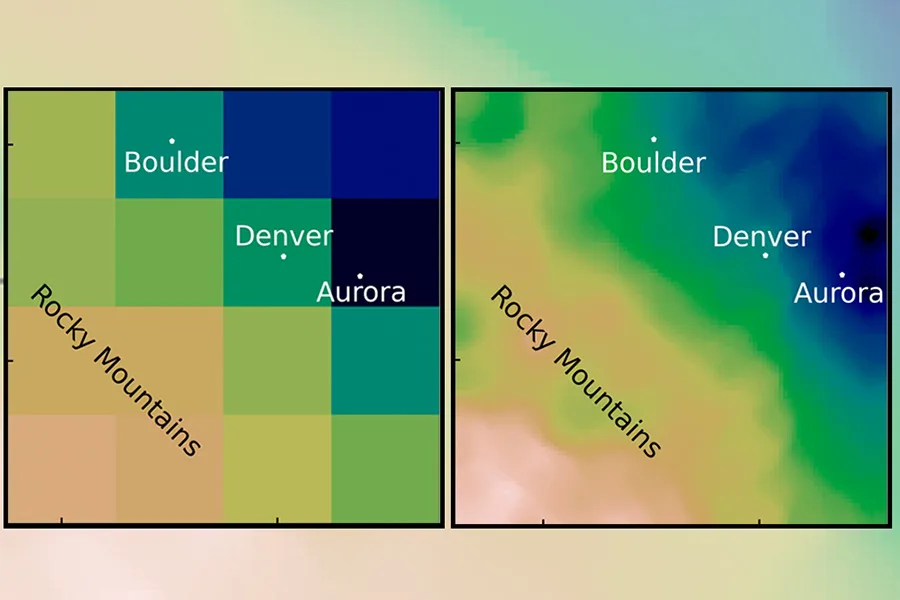
Dans la modélisation climatique, la réduction d’échelle est le processus consistant à utiliser un modèle climatique mondial avec une résolution grossière pour générer des détails plus fins sur des régions plus petites. Imaginez une image numérique : un modèle global est une grande image du monde avec un faible nombre de pixels. Pour réduire l’échelle, vous effectuez un zoom avant uniquement sur la section de la photo que vous souhaitez regarder, par exemple Boston. Mais comme l’image originale était en basse résolution, la nouvelle version est floue ; il ne donne pas suffisamment de détails pour être particulièrement utile.
« Si vous passez d’une résolution grossière à une résolution fine, vous devez ajouter des informations d’une manière ou d’une autre », explique Saha. La réduction d’échelle tente de rajouter ces informations en remplissant les pixels manquants. « Cet ajout d’informations peut se produire de deux manières : soit il peut provenir de la théorie, soit il peut provenir de données. »
La réduction d’échelle conventionnelle implique souvent l’utilisation de modèles fondés sur la physique (tels que le processus de montée, de refroidissement et de condensation de l’air, ou le paysage de la zone) et de les compléter par des données statistiques tirées d’observations historiques. Mais cette méthode est exigeante en termes de calcul : son exécution prend beaucoup de temps et de puissance de calcul, tout en étant coûteuse.
un peu des deux
Dans leur nouvel article, Saha et Ravela ont trouvé un moyen d’ajouter les données d’une autre manière. Ils ont utilisé une technique d’apprentissage automatique appelée apprentissage contradictoire. Il utilise deux machines : l’une génère des données pour entrer dans notre photo. Mais l’autre machine juge l’échantillon en le comparant aux données réelles. Si elle pense que l’image est fausse, la première machine doit réessayer jusqu’à ce qu’elle convainque la deuxième machine. L’objectif final du processus est de créer des données de super-résolution.
L’utilisation de techniques d’apprentissage automatique telles que l’apprentissage contradictoire n’est pas une idée nouvelle dans la modélisation climatique ; là où il peine actuellement, c’est son incapacité à gérer de grandes quantités de physique de base, comme les lois de conservation. Les chercheurs ont découvert qu’il suffisait de simplifier la physique initiale et de la compléter avec des statistiques issues des données historiques pour générer les résultats dont ils avaient besoin.
« Si vous augmentez l’apprentissage automatique avec des informations provenant des statistiques et de la physique simplifiée, alors tout d’un coup, c’est magique », explique Ravela. Lui et Saha ont commencé par estimer les quantités de précipitations extrêmes en supprimant les équations physiques plus complexes et en se concentrant sur la vapeur d’eau et la topographie des terres. Ils ont ensuite généré des schémas de précipitations généraux pour la montagne de Denver et la plaine de Chicago, en appliquant des comptes historiques pour corriger les résultats. « Cela nous donne des extrêmes, comme le fait la physique, à un coût bien moindre. Et cela nous donne des vitesses similaires à celles des statistiques, mais avec une résolution beaucoup plus élevée.
Un autre avantage inattendu des résultats était le peu de données de formation nécessaires. « Le fait que seulement un peu de physique et un peu de statistiques suffisaient à améliorer les performances du ML [machine learning] Le modèle… n’était en fait pas évident dès le début », explique Saha. L’entraînement ne prend que quelques heures et peut produire des résultats en quelques minutes, une amélioration par rapport aux mois nécessaires à l’exécution d’autres modèles.
Quantifier rapidement le risque
Être capable d’exécuter les modèles rapidement et souvent est une exigence clé pour les parties prenantes telles que les compagnies d’assurance et les décideurs politiques locaux. Ravela donne l’exemple du Bangladesh : En observant l’impact des événements météorologiques extrêmes sur le pays, les décisions sur les cultures à cultiver ou sur l’endroit où les populations doivent migrer peuvent être prises dans les plus brefs délais en tenant compte d’un très large éventail de conditions et d’incertitudes.
« Nous ne pouvons pas attendre des mois ou des années pour pouvoir quantifier ce risque », dit-il. « Il faut regarder vers l’avenir et prendre en compte un grand nombre d’incertitudes pour pouvoir dire quelle pourrait être une bonne décision. »
Bien que le modèle actuel ne s’intéresse qu’aux précipitations extrêmes, l’entraîner à examiner d’autres événements critiques, tels que les tempêtes tropicales, les vents et la température, constitue la prochaine étape du projet. Avec un modèle plus robuste, Ravela espère l’appliquer à d’autres endroits comme Boston et Porto Rico dans le cadre d’un Projet Grands Défis Climat.
« Nous sommes très enthousiasmés à la fois par la méthodologie que nous avons élaborée et par les applications potentielles qu’elle pourrait conduire », déclare-t-il.


